Since the release of Red Hat Virtualisation (RHV) 4.1 back in 2017 we have seen the inclusion of Disaster Recovery (DR) solutions. The aim of these solutions is to allow customers to deploy their RHV infrastructure to span multiple sites and allow failover of virtual machines in the event of a disaster. This post will take a look at these Disaster Recovery solutions.
It is worth noting that these DR solutions are part of the core RHV product and are NOT part of a separate subscription offering. There is no per Virtual Machine (VM) cost or similar charge for protecting your workloads.
Overview
RHV 4.1 was released back in 2017 and we introduced an Active/Active implementation. With the release of RHV 4.2 in May 2018 we introduced additional disaster recovery capabilities. We can now deploy an Active/Passive architecture spanning two sites. Let’s take a look at the different implementation options.
Active/Active
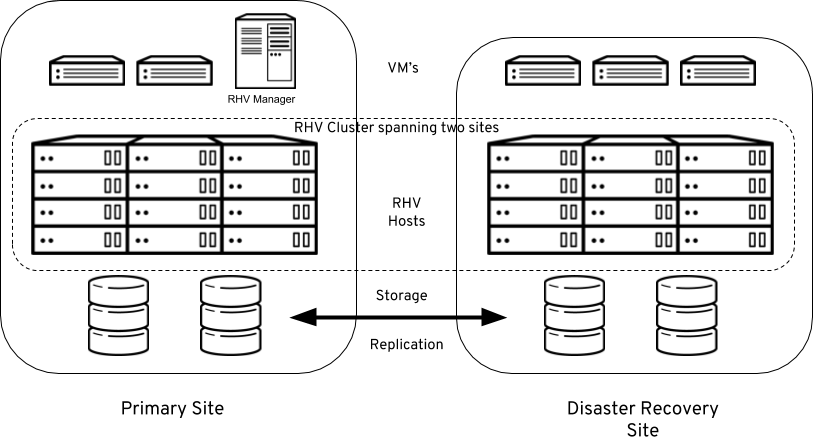
The Active/Active architecture can span two sites. With this implementation we deploy a single RHV cluster with RHV hosts spanning both sites in a stretch cluster configuration. A single RHV Manager is responsible for managing both sites. The RHV Manager itself could be self hosted or standalone (self-hosted simply means the RHV Manager is a VM running on the hypervisors it is managing).
As both sites are active at the same time and VM’s can effectively run at either site at any given time we require synchronously replicated storage that is writeable at both sites at the same time.
In addition to the storage replication we also need a stretched network between sites. As we are deploying a single cluster across both sites we need all of the RHV hosts to be in the same Layer 2 network segment. Also VM networks need to be stretched between sites so that that VM’s can migrate or failover to the secondary site and maintain network connectivity.
VM to RHV Host affinity can be used to ensure VM’s are running in the Primary datacenter where possible and only failed over as part of a disaster. In the event of a disaster in the Primary site, any VM’s marked as “highly available” will automatically be restarted in the Disaster site without any administrator intervention.
The nice thing about the Active/Active setup is that we just rely on native RHV HA to fail VM’s between sites. It does rely on a storage array that can provide write access to both sites with replication. An example of this would be something like EMC VPLEX.
Here is what an Active/Active configuration looks like. This diagram depicts a the RHV manager as a self-hosted engine which is failed over along with the VM workloads.
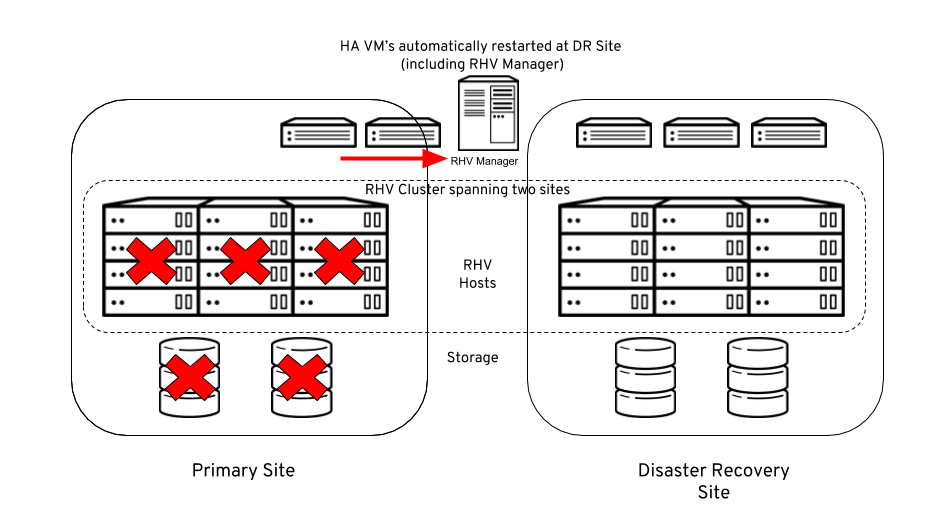
In the event of a failure at the Primary site, any VM’s marked as highly available will automatically restart on RHV hosts in the DR site. Also, as the RHV Manager is self-hosted it is also restarted at the DR site.
Active/Passive
The Active/Passive configuration can also be used across two sites. As the name suggests, only one site is active at any given time. In the event of a disaster, VM’s are failed over from the Primary site to the Disaster site. Once the Primary site is recovered we can then failback. Both failover and failback occur in an automated fashion using Ansible.
Unlike the Active/Active architecture, each site must maintain its own RHV Manager which manages the RHV hosts, storage and networks for that site.
From the storage perspective we require replicated storage between sites. However, the storage is only ever attached to one RHV site at a time so it does not need to be writeable at both sites simultaneously. The same VM networks need to be available in both sites so that VM’s that are failed over can be re-attached to the network.
Here is what an Active/Passive configuration looks like.

In the event of a disaster at the Primary site then we need to ensure that any replication of storage is stopped and that the storage is changed to read/write at the DR site and readonly at Primary site. An administrator can then initiate a failover of VM’s to the DR site.

Summary
Since the release of RHV 4.2 we now have two options for providing Disaster Recovery for our VM’s.
The Active/Active configuration allows us to easily fail workloads between sites using VM HA. However, it does rely on storage which is read/write at both sites at the same time as well as being synchronously replicated.
The Active/Passive solution only requires replicated storage in read/write at one site at a time. However, failover requires manual intervention to switch storage replication and also initiate the VM failover via Ansible.
In the next part of this post we will take a look at how to setup RHV DR in an Active/Passive configuration and how to perform failover and failback.