Ansible Tower is a centralised platform for running and controlling your Ansible automation. It provides a number of key features for running Ansible in the enterprise.
- Role-Based Access Control
- Inventory Management
- Credential Management
- Auditing & Logging
- Clustering & Scale-Out
Job slicing is a new scale-out feature that was introduced in Ansible Tower 3.4 which allows us to run jobs that are distributed across our Ansible Tower cluster. Before we look at job slicing let’s quickly look at clustering and job distribution within a cluster.
Ansible Tower clustering
Ansible Tower can be installed in a cluster to provide a highly available platform for running Ansible. A clustered install provides scale-out capabilities in that different jobs are scheduled across Tower nodes to ensure they are sharing the load. However, each individual job is run on a single Tower node only. If I run a job against 1000’s of servers then a single Tower node runs this job and it must have enough capacity to run this job in a timely fashion. Let’s look at how we calculate concurrency and capacity in Ansible Tower.
Calculating Capacity
Ansible uses forks to determine how many hosts to automate against in parallel. By default 5 forks are spawned but we can override this if we are automating against a large number of hosts. For example, I may run a configuration management playbook every 1 hour to ensure my hosts are in a desired state. If I run that playbook against 1000’s of nodes with only 5 forks then this will take some time to complete.
We can calculate the number of available forks based on memory capacity or cpu capacity depending on the nature of the workload.
memory capacity
Protecting memory capacity is the default configuration and allows us to overcommit cpu while ensuring we don’t run out of memory. To calculate the number of forks we remove 2048MB memory for the running of Tower services and then divide the remaining available memory by mem_per_fork - which defaults to 100MB:
(mem - 2048) / mem_per_fork
For a Tower node with 4GB memory this results in a capacity of around 20 forks:
(4096 - 2048) / 100 = 20
cpu capacity
For cpu capacity we multiply the number of cpus by fork_per_cpu - which defaults to 4.
cpus * fork_per_cpu
For a Tower node with 4 cores:
4 * 4 = 16
If I were to run a job with more forks than the calculated capacity, then I run the risk of performance issues or running out of resources on my Tower nodes.
Job Slicing
As previously mentioned, when a job is launched in Ansible Tower, it is executed on a single node in the cluster. So effectively, ansible-playbook is run from a single node. This means that a job is limited to the number of forks on a single Tower node. If we are executing a playbook across a large number of hosts then we are not making use of all of the available capacity in our cluster.
Job slicing is a new feature of Ansible Tower 3.4 and helps to address this issue. Job slicing allows us to distribute a job across multiple Tower nodes. It does this by splitting the inventory into slices. A workflow is then created for us with multiple instances of our job being run on each slice of our inventory. For example, if I have 30 nodes in my inventory and I decide to create 3 slices then a workflow is created with three jobs - each being executed on 10 nodes in parallel. Obviously, I need 3 Tower nodes in this example so that my three job slices can be executed across the three hosts.
Using job slices
To demonstrate job slicing, I have a three node Tower cluster. My inventory contains 49 hosts for me to automate against. Here is the available capacity in forks reported by my hosts.

My Tower hosts can each safely spawn up to 27 forks based on memory capacity. If we look at the following job template we can see that I have specified 30 forks - I run the risk of exhausting memory resources. Also note that I only have one job slice configured - this is the default when creating a new job template.
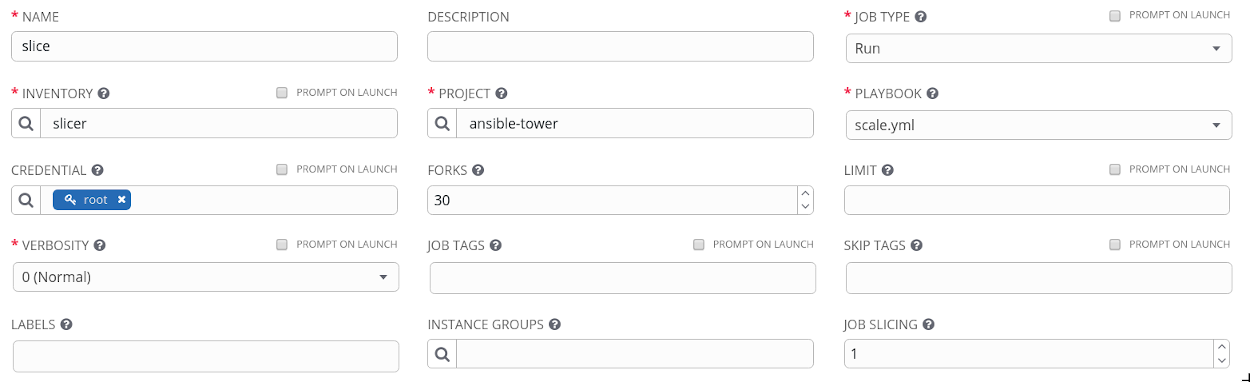
When I launch my job we can see that my playbook is being run on a single Tower node. As I have allocated more forks than I safely have capacity for I am over-allocated on capacity. My other two Tower nodes are just relaxing at this point with no work scheduled on them.

Now I’ll re-configure my job template so that it utilises three slices.
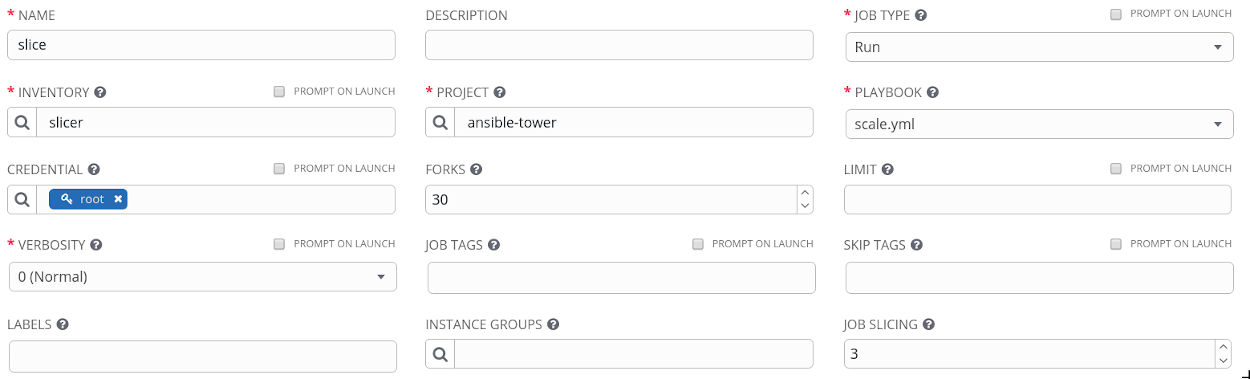
This time when I launch my job template, a worklfow is automatically generated.
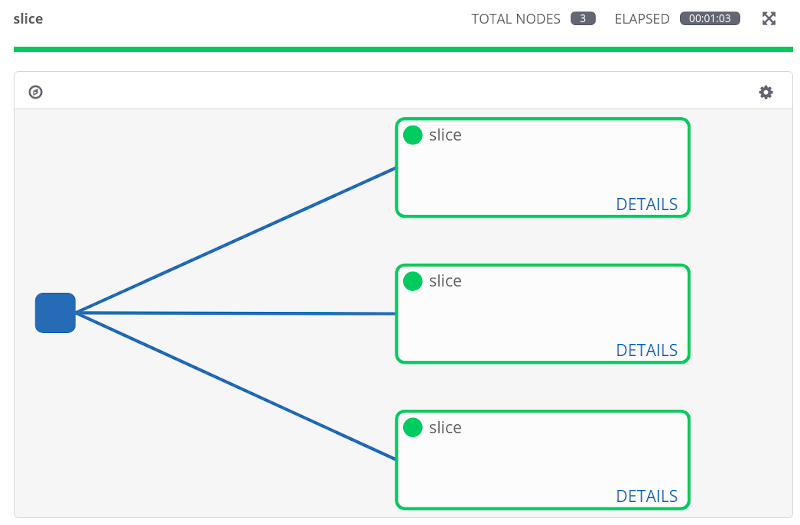
If we look at one of the individual jobs within the workflow we can see that this is slice job 1 of 3. Also, note that this job is being run on a “slice” of my inventory - 16 hosts.

Finally, we can see that capacity is now being utilised across all three of my Tower nodes.

Summary
Job slices provide an additional method for scaling Ansible automation with Ansible Tower. By default, jobs are distributed across Tower nodes in a cluster but each individual job is only ever run from a single Tower node. Job slicing allows us to split a single job so that it is run across multiple nodes to provide additional scale-out capacity.